- Published on
What is Feature Pyramid Network (FPN)?
- Authors
- Name
- Farid Hasainia, PhD
- @ai_fast_track


💡 Overview
Feature Pyramid Network is designed to combine the features from different levels of a convolutional network, in order to better detect objects at different scales.
Table of Contents
🧠 KEY TAKEAWAYS
- A feature pyramid network (FPN) is a neural network used in computer vision for object detection.
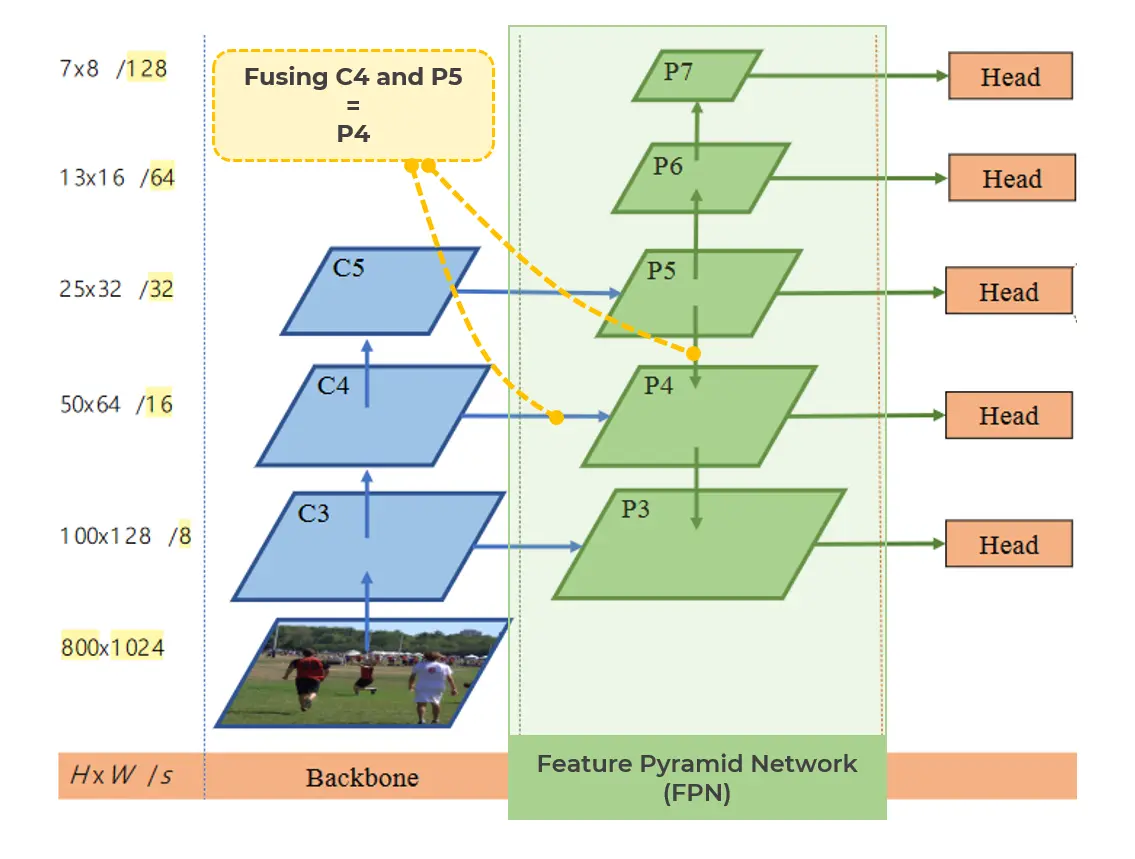
The first step in the network is to create a convolutional feature pyramid (C1 -C7) from the input image.
C1 (conv1) is the first feature map with half size of the image input
C7 (conv7) is the output of the last convolutional layer.
For eaxample, C2 is good at detecting small objects, C3 is good at detecting medium sized objects, and C4 is good at detecting large objects, and so forth.
C2 is detail-aware (zoom in) whereas C5 is context-aware (zoom out).
In order, to make benefit from context-aware features, we need to fuse the features from adjacent layers .
That's why we use a feature pyramid network (FPN)
🤔 What is Feature Pyramid Network?
Feature Pyramid Network is designed to combine the features from different levels of a convolutional network, in order to better detect objects at different scales.
You probably already heard that FPN builds high-level semantic feature maps at all scales. What does that mean?
It means we combine feature maps from different levels of the network, and then use those feature maps to create a higher-level feature map.
By doing so, we create a strong semantic feature map at each scale.

As you can see, P2/P3 feature maps highlight the details (low-level semantic) whereas P5/P6 feature maps highlights the context (high-level semantic).


💠 Feature Pyramid Network (FPN) Types
There are at least four types of FPN: FPN, BiFPN, NAS-FPN, and BiFPN.
Check the Feature Pyramid Network (FPN) Comparison to see which one is the best for your use case.


✍️ Some other observations:
FPN is used in both One-Stage Object and Two-Stage Object Detection Architectures
The model diagram corresponds to the One-Stage Object Detection Architecture
The (P3-P5) layers are also referred as the Convolutional (C3-C5) Layers in some papers
P7out is simply referred as P7 in other papers
There are other more FPN sophisticated design. YOLO-ReT proposed a new design. Check out my YOLO-ReT post for more details

🎯 Actionable resources for FPN
You can train one of the many object detection models using FPN, in this notebook: Getting Started in Object Detection Notebook
👨💻 Code snippet
# VFNet Model
if selection == 0:
model_type = models.mmdet.vfnet
backbone = model_type.backbones.resnet50_fpn_mstrain_2x
# RetinaNet Model
if selection == 1:
model_type = models.mmdet.retinanet
backbone = model_type.backbones.resnet50_fpn_1x
# YOLOX Model
if selection == 4:
model_type = models.mmdet.yolox
backbone = model_type.backbones.yolox_s_8x8
...
If you want to have a peek at the code on how FPN is used in the RetinaNet in the MMDetection library, check out this code snippet:
Source: MMDetection RetinaNet Configuration File
# RetinaNet model settings
model = dict(
type='RetinaNet',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs='on_input',
num_outs=5),
...
In the above code snippet, the backbone is a ResNet50. The neck is a FPN
in_channels (List[int]): Number of input channels per scale. in_channels=[256, 512, 1024, 2048]
out_channels (int): Number of output channels (used at each scale). out_channels=256
start_level (int): Index of the start input backbone level used to build the feature pyramid. start_level=1
num_outs (int): Number of output scales (P3 to P7). num_outs=5
📚 References
📰 Paper for more details.